

If you're in the boat where you're desperate for a good night's sleep, but you end up waking up at 2-3 in the morning – your thoughts hopelessly buzz as you aren't able to sleep again. I'll tell you what: melatonin pills are NOT your friend here.
Yes, you can take melatonin to induce sleepiness, but melatonin is just a signal hormone to tell your body it's time for sleep, nothing more. What ends up happening, particularly at higher doses (i.e. 10mg) is that it flushes out everything in your body that actually results in you sleeping, so that you're left stranded in the middle of the night.
Instead, what I do is probiotic supplements, because so many things in your body and mind rely on decent processing of your intestinal lining. If you're having gut issues and/or you're not having a good diet, odds are you're going to feel like how a woke libtard does.. powerless, without the instinctual energy to do anything or think straight, and internally moody as hell. This is the main reason why leftists are characteristically insufferable, flaky and petulant, while you'll hear them rant to you about their morals and how things ought to be, every chance they get, while their contrarian character chafes upon anyone with an ounce of honesty in their hearts. (I used to be in this boat myself.)
Anyways, you want something that has at least 50 billion CFU, guaranteed minimum. Probiotic cultures deteroriate over time; you'll have brands that claim to have such-and-such CFU, when in reality that's just the amount of CFU that it initially has. The really good probiotics will have prebiotics included as well (with fibre, etc.).
If you're just starting out, take two probiotic pills at once in a day to adapt the culture in your stomach lining. This phase won't take longer than a day or two, then one pill in the morning. No matter what the packaging says, store the bottle in your fridge to better preserve the pills.
Then at night, before bed, you're going to take a spoonful of raw extra virgin olive oil before bed, to counter-act the inflammation that may be present in your body/brain, that prevents you from falling asleep naturally. Be sure you're drinking plenty of water thoughout the day, and I don't mean Gatorade.
ZFS isn't a perfect filesystem. For starters, there is no option to directly defragment anything in a pool (at least, not yet). But for what it does, it's amazing at keeping your data going. The most important feature it has though is the ability to snapshot a dataset (or a ZVol for that matter), so you can instantly revert to say, a state of five minutes ago or even a month ago if it turns out something has gone bad. This works, even when using HDDs (those spinning, mechanical drives), thanks to the fact that ZFS uses copy-on-write – data isn't overwritten in-place, but rather new writes are poured out over the free space like so (moar info here):
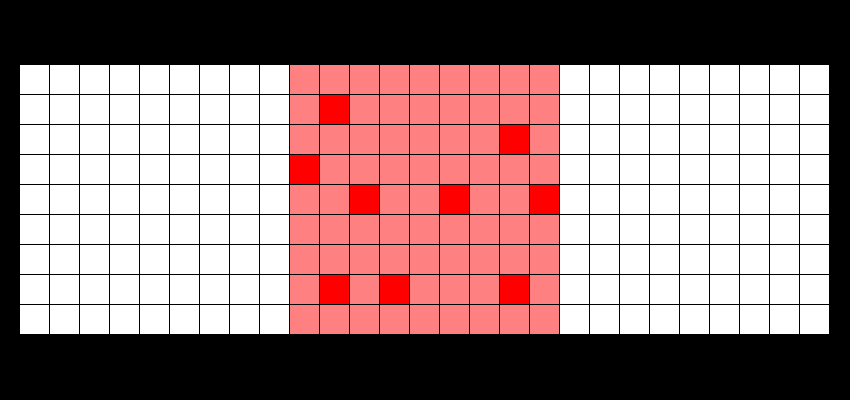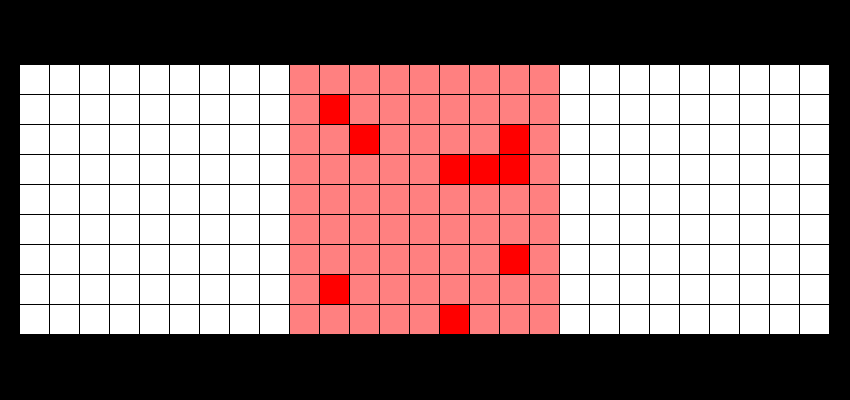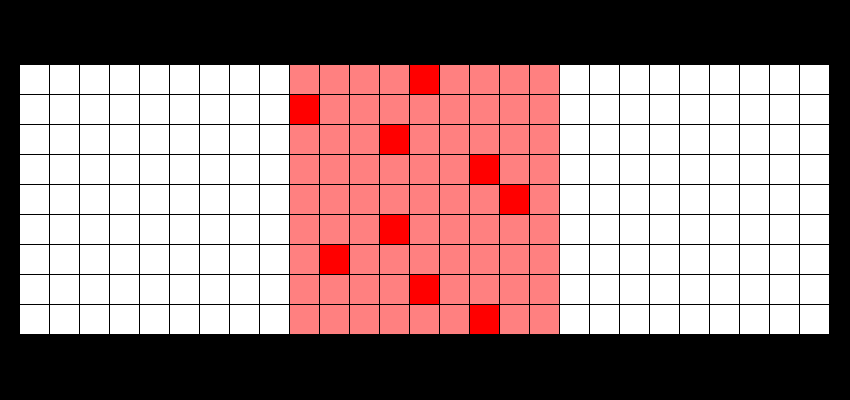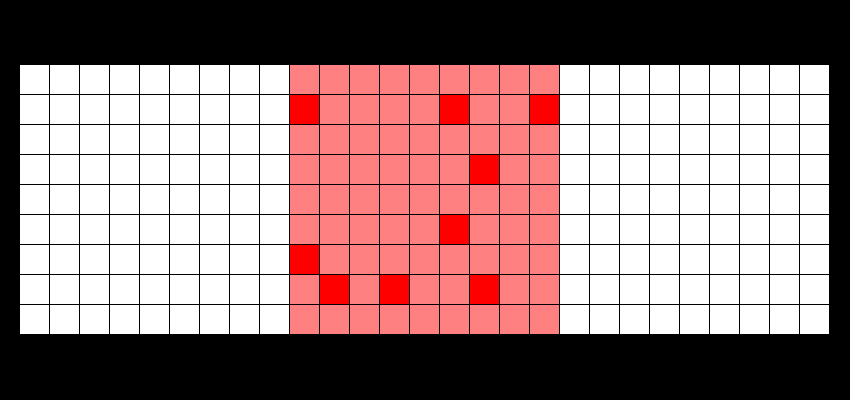
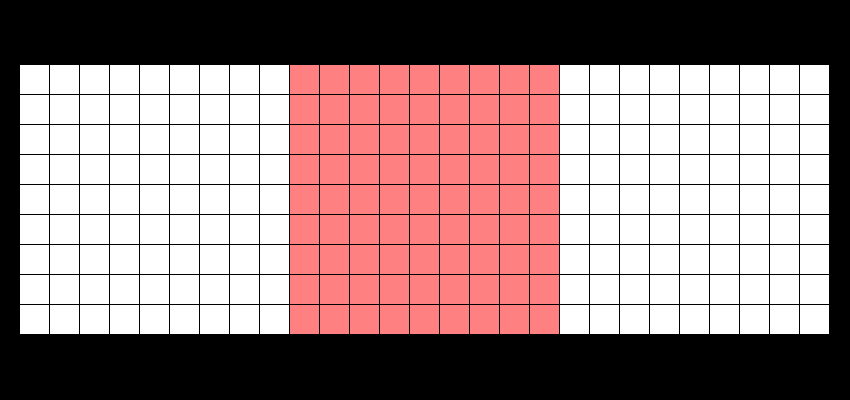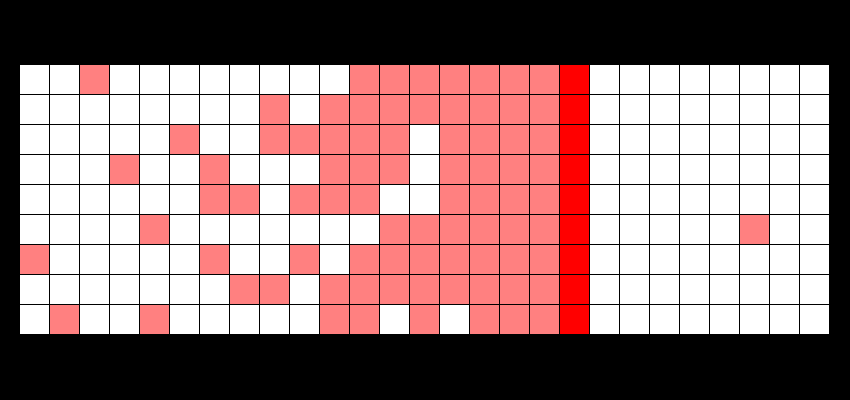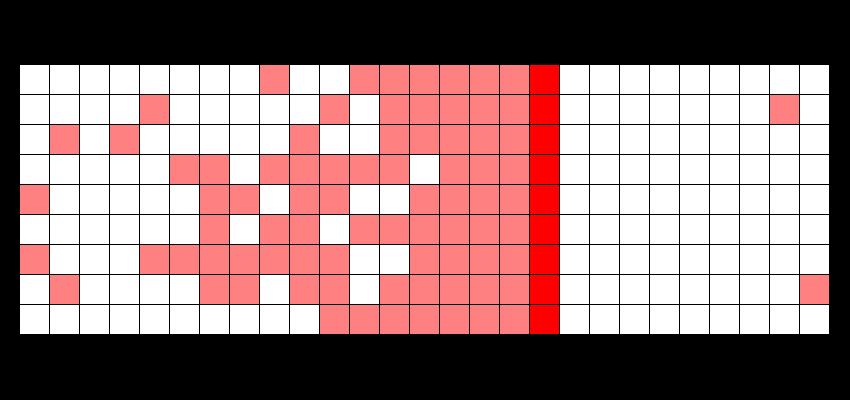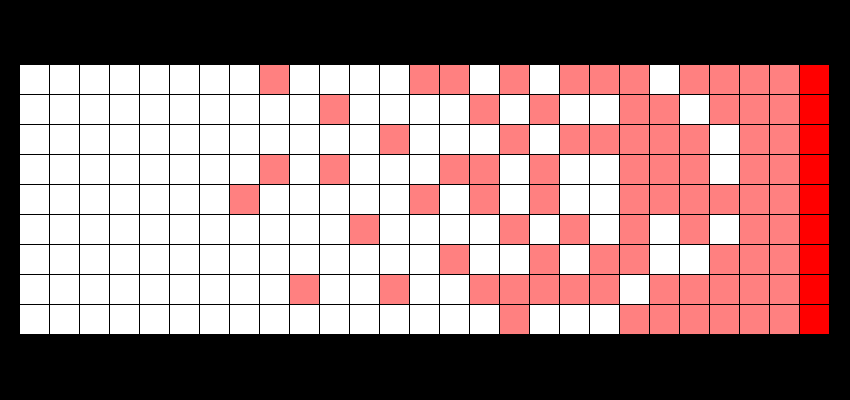
ZFS, besides the snapshotting (I use sanoid for automating my zpool snapshots), is incredibly good for preventing data corruption by unfinished writes: i.e. your PC goes on the fritz and you reboot improperly, which will happen if you're tinkering around with settings. On Linux or bare-metal Windows, which relies on journalling for its file systems, you're going to be met with "Recovering journal" or "Checking disk" (which sometimes doesn't solve anything), but under ZFS, your files are left consistent.
One further point, is that you can accelerate read/writes using spare memory (ARC) as well through a fast disk (L2ARC) you can spare like an SSD or an NVMe drive. The result is that with storing games and other frequently accessed data on your HDDs, it will load from the ARC and L2ARC for faster loading times.
Using L2ARC was a mistake on my part. With what little memory I have left for the host VM, it results in thrashing for the L2ARC leading to periods of VM non-responsiveness under heavy I/O load.
Now, I'm not any expert on using ZFS, I'm still experimenting and what I'm going to say next will apply mainly for using KVM virtualization under QEMU. For my use case, I've converted all my drives to using zpools, with my NVMe drive serving as both L2ARC and dedicated SLOG for each of my HDDs.
How do I use these ZFS pools with my Windows VM? The answer is block storage. There are multiple ways, with the traditional way being to store the "drive" in an .img/.qcow2 file. But to fully take advantage of ZFS's features with minimal overhead, using a ZVol (ZFS Volume) is the way to go. I won't provide instructions on how this is done, aside from creating the zpool on top of the disk itself, configuring the zpool to use LZ4 compression (even though it means extra processing, modern CPUs are fast enough that this is done seamlessly, so that the reduced data allows faster reads and writes from the storage) and atime=off, and then creating a sparse zvol with the capacity of the entire drive.
Now, you'll find answers online which basically say "Oh, but using files on a dataset is just better!" But the problem is in the overhead, as your disk access has to go through additional layers, compared with accessing the zvol directly in KVM:
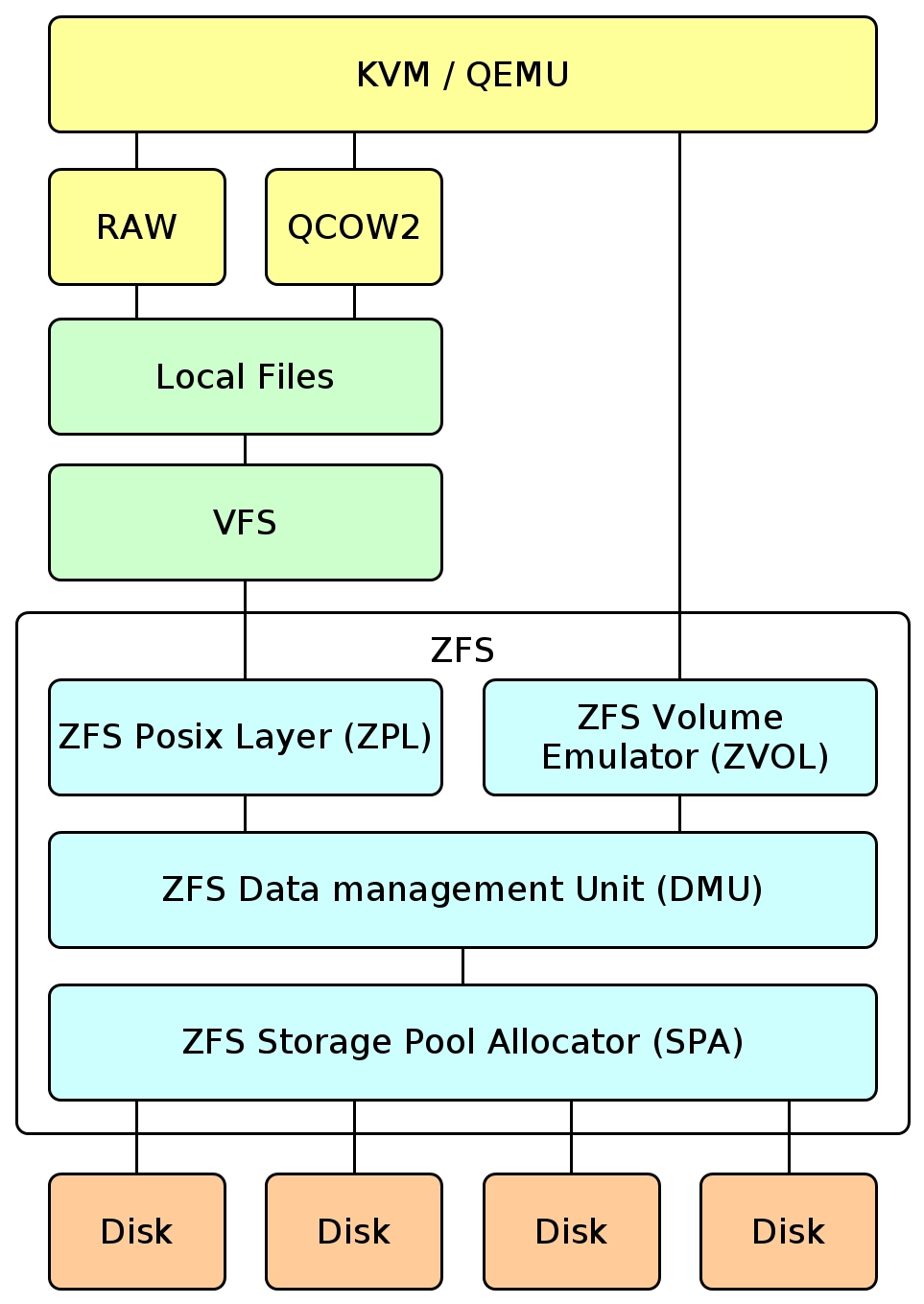
I'd like to mention /u/mercenary_sysadmin (Jim Salters) from Reddit, who shills for this hacky solution:
In my testing, no. I saw no benefit at all from using zvols instead of .qcow2 files, and you introduce a significant amount of maintenance headaches with zvols - first up being, you can't take a snapshot of a 1TB zvol unless you have at least 1TB free. (source)
If you explore deeper, you'll see his rationale on his blog:
If you don’t have at least as much free space in a pool as the REFER of a ZVOL on that pool, you can’t snapshot the ZVOL, period. This means for our little baby demonstration here we’d need 15G free to snapshot our 15G ZVOL. [...] Think long and hard before you implement ZVOLs. Then, you know… don’t. (source)
Have you ever stopped to ask why it is you can't snapshot that zvol? In a little issue opened up on GitHub, Shados says:
You can snapshot a zvol that occupies 85% of your pool, you just need to change its refreservation to a normal reservation (or remove its reservation entirely, making it a sparse zvol). Both of those have potential risks / consequences in turn, of course, so read the ZFS man page entries for them carefully and give it some thought before doing so.
ZFS uses refreservation by default for zvols because otherwise in a free-space contention scenario you could accidentally run out of space for a zvol due to snapshots, despite thinking you had sufficient space reserved from the beginning. refreservation reserves space in the pool for the dataset without allowing children of that dataset (relevantly here, including snapshots) to consume from that reservation, while a normal reservation will be consumed by child datasets. (source)
This is why I use sparse (thin-partitioned) zvols, so I can have the unused storage space for snapshots, despite having the volume's capacity filling up the whole drive. Note that as you add or update files on a pool, the snapshot sizes grow in proportion to the amount of data that has to be rolled back, so remember to clear out old snapshots if you see your zpool's storage grow uncomfortably low. If your VM's storage is almost full, you'll have little room to snapshot.
Also, Jim mentions the following about using .qcow2 files for convenience:
ZVOL won’t pause the guest if storage is unavailable. If you fill the underlying pool with a guest that’s using a zvol for its storage, the filesystem in the guest will panic. From the guest’s perspective, this is a hardware I/O error, and the guest and/or its apps which use that virtual disk will crash, leaving it in an unknown and possibly corrupt state. (source)
This sounds like a major put-off. But there's an easy workaround you can put in libvirt:
<disk type='block' device='disk'>
<driver name='qemu' type='raw' cache='none' error_policy='stop' io='native' discard='unmap'/>
<source dev='/dev/zvm/secure/entertainer-root'/>
<blockio physical_block_size='32768'/>
<target dev='sda' bus='scsi'/>
<address type='drive' controller='0' bus='0' target='0' unit='0'/>
</disk>
error_policy='stop'prevents the VM from crashing should the parent dataset become full (seemed to be a major issue with ZVOLs at first). The VM is paused and can be resumed when the write can be completed (it pauses again otherwise). (source)
What's the whole point? The problem in life with these so-called experts is that they really don't know what they don't know, despite the air of unquestionable competence about them. It was a hassle to bring my personal data off from merely using RAW files on a dataset when I found out that this hacky answer is essentially ripping me off in the long-term:
Don't overthink it. This is a really easy storage workload. Just put your raw file on a dataset, take snapshots, enjoy life. (source)
One thing that I've never found in a Google search: why does my audio skip when I enable the parameter -overcommit cpu-pm=on in my QEMU/libvirt config?
I suppose you're one of those few people who hate the way your mouse feels sluggish while gaming inside a VM, so you went all the way to reduce DPC latencies.
In my case: if you look under dmesg, you'll see that real-time throttling is enabled. By default, Linux leaves /proc/sys/kernel/sched_rt_runtime_us at 950000, which means that 95% of CPU bandwidth will be allocated for realtime tasks (like your virtual machine under QEMU), while 5% remains in case there's overhead or additional processing that needs to be done.
As a result, you'll experience delay within the VM (like network and audio stutters). If you'll open up htop while your VM's running, you'll see how your VM's vCPUs will fluctuate around 95% or so, but never consistently at 100%.

Now, you can set sched_rt_runtime_us to -1, which grants your VM and other realtime tasks total dominance, but doing so at first will put your VM and your entire system in a frozen standstill. Why? Because despite having CPU pinning for your VM, and having isolcpus and the like under your kernel's boot parameters, you will still have running processes on your seemingly dedicated CPU cores.
These processes are hardware interrupts, spread out by the kernel across your CPU. Setting sched_rt_runtime_us to -1 means that your VM chokes out the hardware interrupts, meaning that your whole PC won't be processing network, hard drive read/writes, etc. You can see how the IRQs are spread out across your CPU with the following command: watch -n 0.5 cat /proc/interrupts
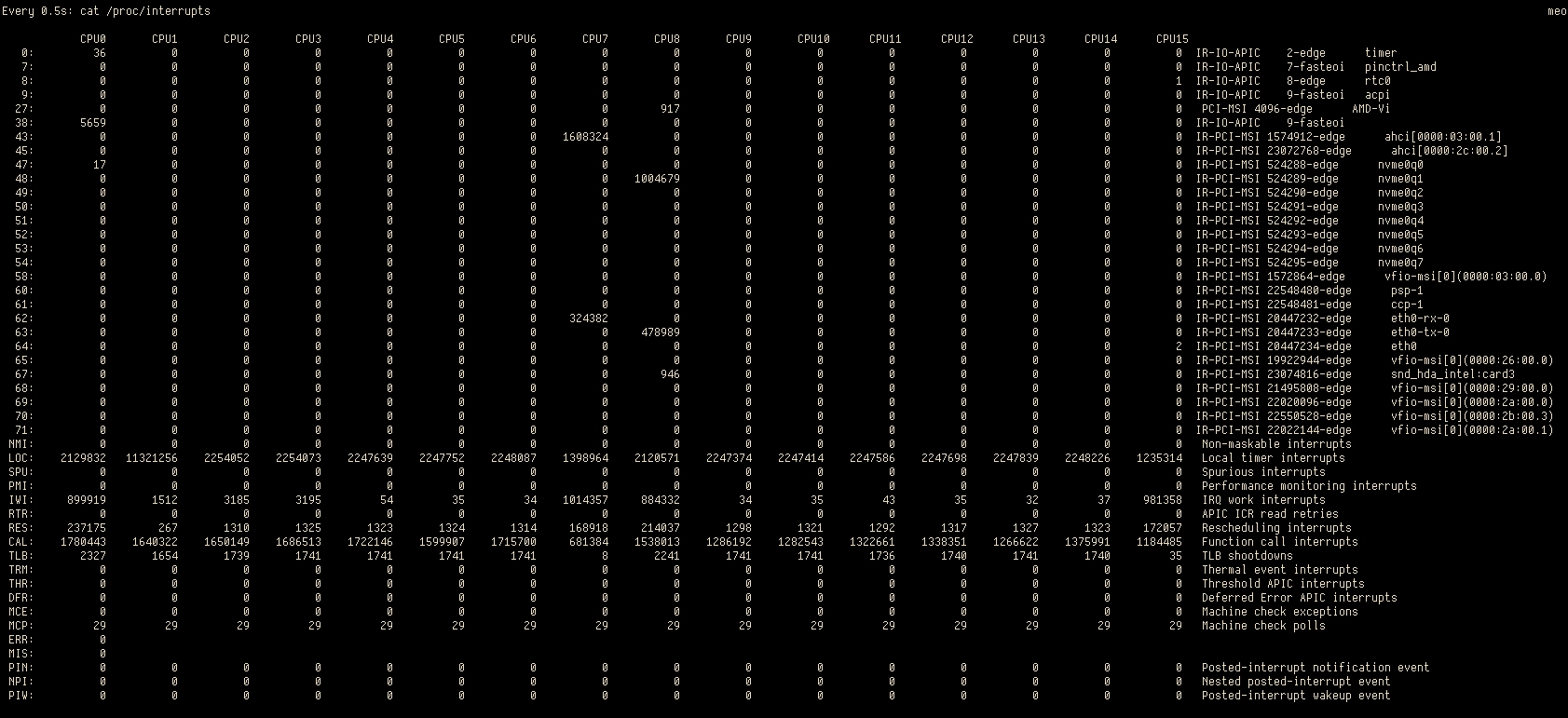
You'll need to move these interrupts to the CPU cores not hogged by your VM - that are reserved for your host Linux; you can also put the interrupts on the emulatorpin/iothreadpin cores, since these cores just sit idle otherwise with nothing to do. To do so, add in the kernel parameter in GRUB: irqaffinity=[cpulist], where [cpulist] is where you select the CPU cores to pin interrupts to, like you would with isolcpus.
This moves the interrupts away from your VM's vCPUs. But we're not done yet; with what few processing cores you have left, most likely your IRQs will overlap, sharing the same core and leading to micro-stutters. To fix this, obtain irqbalance which will automatically distribute the hardware interrupts across a given subset of CPUs. Specify the environment variable:
IRQBALANCE_BANNED_CPUS= CPU mask in hexadecimal: i.e. 0000FCFC to block cores 2-7 + 10-15 (the CPU mask is read backwards)
when running IRQbalance, so that it'll know not to place IRQs on your CPU cores dedicated to the VM.
On my end, I run irqbalance as a background service. I don't know which init system you might be running, but most likely you'll have to manually set up the service file for irqbalance, so to run on every boot.
To verify that IRQBalance is ignoring the right CPU cores, you can use irqbalance-ui (run it as sudo):

Now, when you start your VM with cpu-pm enabled, and sched_rt_runtime_us to -1, everything runs buttery smooth.
